Reversing Technology
A blog on reverse engineering technology and reverse engineering technology.
Easily getting type information of a common ELF library into Ghidra
Intended Audience:
- already familiar with the very basics of package building process on Arch Linux, i.e.
makepkg - basic idea behind Ghidra Data Type archives
Prelude
I wanted to look into a little binary that is available to remap the keys on a little 4-key keyboard I bought recently (Amazon Link).
Binary is available for Linux, macOS and Windows, I am on Linux, so I looked into that version. First two major annoyances: It’s C++ and it heavily uses libusb and the structures libusb uses. This blog post is about the latter issue.
How to get the Type Information from the Library Source Code into my Ghidra Project ?
libusb is an open source library, so it would be absurd to recover the function signatures and structs ourselves by reverse engineering the library. But reading the source code and manually specifying the function signatures and structs would also be way too much effort. So surely there is some more efficient way to do this on demand when needed or at scale before.
The Ghidra DWARF Parser
DWARF Format
DWARF is the data format for debugging information that accompanies an ELF binary (get it?), that makes debugging a lot more tolerable. Most importantly it contains all the relevant information about the struct layouts and function signatures and Ghidra automatically parses this and applies it to a binary when importing. So as soon as we have a library that has this available, we can just import it into Ghidra.
Debian actually has a prebuilt libusb-dbg package. At first, I assumed that this was just the external DWARF information, which Ghidra doesn’t support, but at the time of writing of this post I think that this might have also worked. But because this will not always be the case, and not every package is in the Debian repositories, we will do it ourselves in this case. This also makes it clear how to change any other relevant flags if desired.
Compiling with debug information on Arch Linux
First step is to fetch the PKGBUILD from the Arch Build System. Either use SVN or the custom asp tool, it shouldn’t matter as long as you end up with a PKGBUILD file.
Check if the PKGBUILD uses a regular ./configure, then make if yes, then the following approach should work, otherwise there might be changes needed.
Make a copy of /etc/makepkg.conf and change the following lines:
-
OPTIONS=(...)must contain!stripanddebug, so the package is built with debug information and it isn’t stripped out afterwards. -
DEBUG_CFLAGSshould contain-gdwarf-4because Ghidra doesn’t support the DWARF Version 5 format yet and the currentgccversion in Arch already uses this by default.-Ogbecause that supposedly adds more information than just-g
Now you can simply run:
makepkg --config ./makepkg.conf --noarchive to compile the package using your new makepkg.conf. --noarchive skips the step of compressing this into an actual package.
There should now be a pkg directory containing your compiled package, with the .so file of your library. Check that this indeed contains debug information by using e.g.:
$ file pkg/libusb/usr/lib/libusb-1.0.so.0.3.0
pkg/libusb/usr/lib/libusb-1.0.so.0.3.0: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=48b2f2279287029660719af47dd37ab0ec7d37a0, with debug_info, not stripped
The output should contain ` with debug_info, not stripped`, if not something went wrong, for example that the compilation process did not respect the flags.
Importing into Ghidra and extracting datatypes
The following Kotlin Script dumps the recovered function signatures into a .gdt archive file in the current working directory.
import ghidra.app.cmd.function.CaptureFunctionDataTypesCmd
import ghidra.app.script.GhidraScript
import ghidra.program.model.data.FileDataTypeManager
import ghidra.util.Msg
class DumpGDTFromDWARF: GhidraScript() {
override fun run() {
if (ghidra.app.util.bin.format.dwarf4.next.DWARFProgram.isDWARF(currentProgram)){
currentProgram.name
val gdtfile = java.io.File(currentProgram.name + ".gdt")
Msg.info(this, "Dumping to ${gdtfile.canonicalPath}")
val dtm = FileDataTypeManager.createFileArchive(gdtfile)
val cmd = CaptureFunctionDataTypesCmd(dtm, currentProgram.memory) { Msg.info(it, "Dumped to $gdtfile")}
cmd.applyTo(currentProgram)
dtm.save()
dtm.close()
}
}
}
You can run it in the headless analyzer via e.g.:
analyzeHeadless /tmp/ tmp -scriptPath /home/fmagin/GhidraDevel/scripts/ghidra_scripts/ -readOnly -postScript DumpGDTFromDWARF.kt
This script will require the [Kotlin Script Provider for Ghidra, but it could also be easily ported to Python.
The /tmp tmp and -readOnly arguments allow you to not clutter your existing projects. A project named tmp will be created in your /tmp directory, but the results of the analysis will never be written to it because of the -readOnly flag.
You should now have a .gdt archive in your current working directory, the script should also print out the full path to it, in case it ends up in an unexpected place.
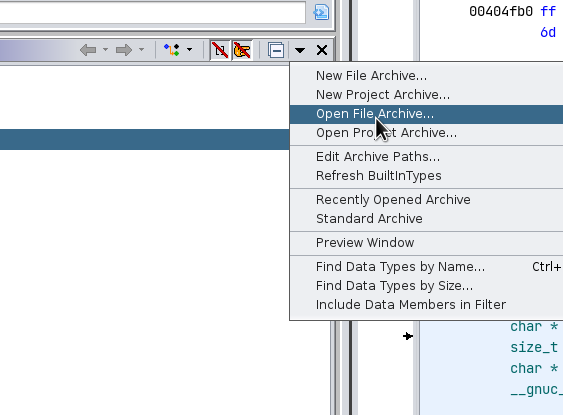
Open this via the Open File Archive... dialog:
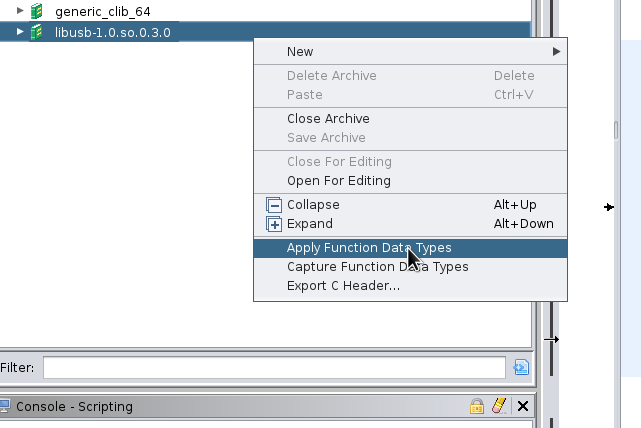
then Apply Function Data Types
Result:
