Reversing Technology
A blog on reverse engineering technology and reverse engineering technology.
Ghidra Dev without Eclipse Part 1: Writing Java Scripts
Preamble
Ghidra provides the really nice experience of setting up an Eclipse Project for you, with all the libraries setup and the ability to create a new script that has a basic skeleton. This is a great user experience and got me started with writing my own scripts pretty much immediately. After a few scripts Eclipse got fairly annoying though, because I am used to the JetBrains toolkit (mostly PyCharm, but they are similar enough). I wanted to have a full dev setup for Ghidra anyway so I started setting things up with IntelliJ. This series of blogposts will cover my entire setup and aims to include every Ghidra related development task running from IntelliJ and if possible as a fully IDE independent setup. This will cover both Java and Python, so writing and debugging Python scripts that run inside the Ghidra context is included.
Setup
This setup is for writing scripts for a non development Ghidra version, i.e. any of the zip files from either the website or Github releases.
The really dumb way (import from Eclipse)
If you already have a setup with Eclipse or just an Eclipse with GhidraDev migrating is fairly trivial.
- If you don’t have one yet create a Ghidra Scripts Project in Eclipse with
GhidraDev -> New -> Ghidra Script Project. The details are documented inExtensions/Eclipse/GhidraDev/GhidraDev_README.html - Open IntelliJ and use
Import Projectto import the Eclipse Project. Most of the defaults work for me, the only thing I need to change is that the Project SDK should be 11 (/usr/lib/jvm/java-11-openjdkon Arch) - IntelliJ might complain about an invalid JDK after the import and open the dialog to select a Module SDK. In the dropdown select
Project SDK (11)and press ok. - You now have an IntelliJ Project with your own Ghidra scripts and all the shipped ones. All the imports should be recognized and you can both properly write scripts with all the introspection and explore the code behind the API your scripts use.
This still requires some files from the Eclipse Project, so you can’t just delete the Eclipse project Folder. I wouldn’t recommend this setup, but it is a quick way to get started.
Without using Eclipse
- Create a new IntelliJ Project
- Java with Project SDK
11, no libraries or frameworks, no template, whatever folder you want - [OPTIONAL] Rename the
srcdirectory toghidra_scriptsfor consistency - Two possibilities to add the dependencies for your module:
- Easy One (thanks to Tamir Bahar for telling me about this )
- Open a terminal and navigate to your Ghidra folder of the version you want to use
- Run
support/buildGhidraJar. This puts aghidra.jarin the root of your Ghidra install - In IntelliJ, open the project and add the JAR as an dependency
- Don’t add the detected
ghidra_scriptroots, just the/
- Alternative: Add all the JARs manually, or via some recursive feature. Because the previous way works for me I never tried this.
- Easy One (thanks to Tamir Bahar for telling me about this )
File -> New -> Module from Existing Sources- Select the Ghidra root, so
ghidra_9.0.4. This should contain theghidra.jar - Select
Create module from existing sources - IntelliJ should show all the
ghidra_scriptsfolders now, make sure they are all marked - Unmark all the libraries (click one,
SpacebarDownArrowSpacebar…) except the one named like your root e.g.ghidra_9.0.4that contains theghidra.jar - Result should look like
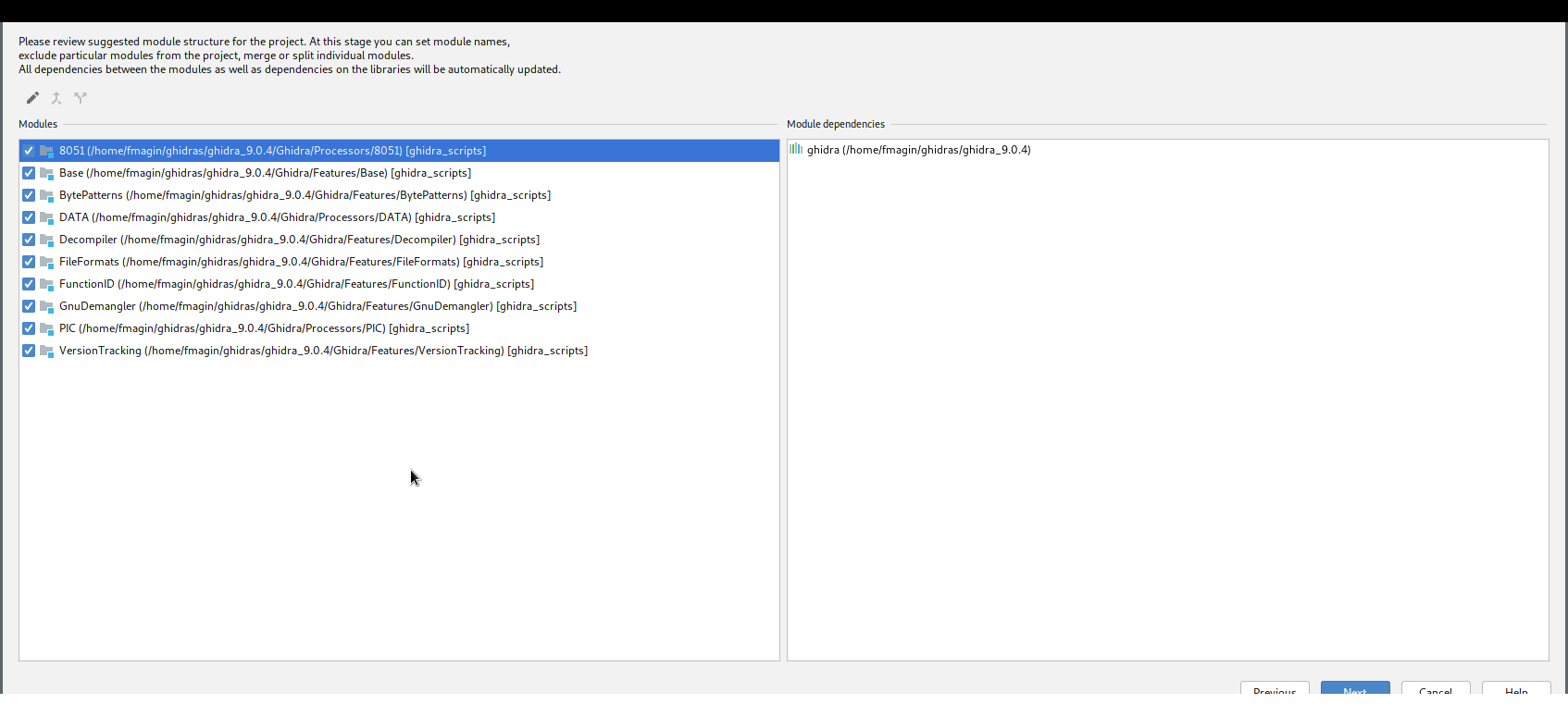
- Select the Ghidra root, so
- IntelliJ should now have added all the shipped
ghidra_scriptsfolders, and you can inspect and edit them.
Templates
Add a template named GhidraScript(or whatever you want) with the following content:
//@category
//@keybinding
//@menupath
//@toolbar
import ghidra.app.script.GhidraScript;
public class ${NAME} extends GhidraScript {
@Override
public void run() throws Exception {
}
}
You can extend it with any template variables ( like ${NAME}) you care about like author, creation date, copyright, etc.
There should be an New -> GhidraScript Option now, when a source directory is selected.
Improvements
This setup can still be improved in some aspects. With just the added JAR as a dependency the IDE has to resort to decompiling if inspecting or debugging Ghidra core code. This is still readable code, but the Javadoc annotations are missing which can be quite helpful. There is probably a nice way to get around this by providing the sources instead of the JAR (or both?) but because I have the Ghidra git locally I mostly use that. I will update this post when I find out a better way, either by getting annoyed by it enough or someone else telling me.
Conclusion
Writing Ghidra Scripts is a good first step to playing with the Ghidra API. Ghidra lacks some features which you might miss from IDA, but often they are a lot easier to implement yourself than they seem to be. One example for this is parsing structures into a datatype via a simple interface like IDA and not having to resort to the Ghidra header parsing process that is more tedious and involves the GUI. The actually logic to implement this is around 4 lines of as a Ghidra script. The details will be covered in a separate blogpost, if you just want the result: https://github.com/fmagin/ghidra_scripts/blob/master/ParseDataType.java